温馨提醒
如果文章内容或图片资源失效,请留言反馈,我们会及时处理,谢谢
本文最后更新于2024年1月10日,已超过 180天没有更新
这是一个离线运行的本地语音识别转文字工具,基于 fast-whipser 开源模型,可将视频/音频中的人类声音识别并转为文字,可输出json格式、srt字幕带时间戳格式、纯文字格式。可用于自行部署后替代 openai 的语音识别接口或百度语音识别等,准确率基本等同openai官方api接口。
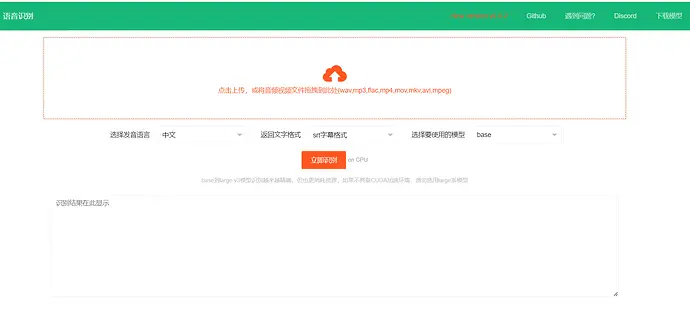
GitHub地址:https://github.com/jianchang512/stt
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

评论0+