温馨提醒
如果文章内容或图片资源失效,请留言反馈,我们会及时处理,谢谢
本文最后更新于2024年2月14日,已超过 180天没有更新
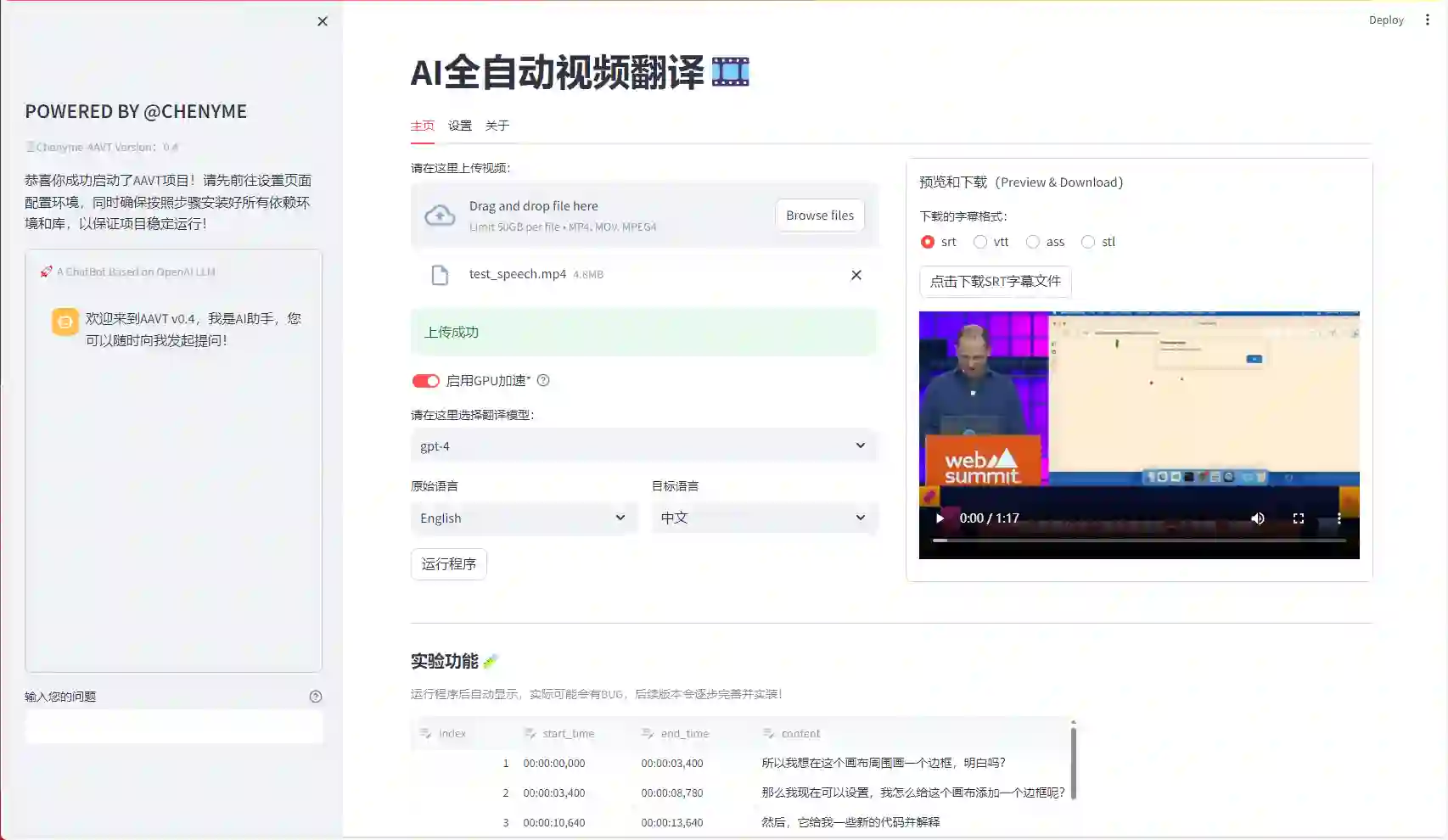
Chenyme-AAVT V0.4是一个全自动视频翻译项目。利用Whisper识别声音,AI大模型翻译字幕,最后合并字幕视频,生成翻译好的带字幕的视频。
该项目旨在提供一个简单易用的全自动视频翻译工具,帮助您快速识别声音并翻译生成字幕文件,然后将翻译后的字幕与原视频合并,以便您更快速的实现视频翻译。主要基于 OpenAI 开发的 Whisper 来识别声音和 LLMs 辅助翻译字幕 ,利用 Streamlit 搭建快速使用的 WebUI 界面,以及 FFmpeg 来实现字幕与视频的合并。
Tips:推荐选用 Faster-whisper 和 Large 模型以获得最好的断句、识别体验。
注意: 首次使用 Whisper 模型时需下载,国内建议开启 VPN 下载。启用 GPU 加速需下载 CUDA 和 PyTorch,且保证PyTorch 版本与 CUDA 匹配,否则程序识别失败会默认禁用GPU加速。
项目亮点:
- 支持 faster-whisper 后端
- 支持 GPU 加速
- 支持 ChatGPT、KIMI 翻译
- 支持多种语言识别、翻译
- 支持多种字幕格式输出
- 支持字幕、视频预览
GitHub地址:https://github.com/Chenyme/Chenyme-AAVT
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

评论0+