温馨提醒
如果文章内容或图片资源失效,请留言反馈,我们会及时处理,谢谢
本文最后更新于2024年2月20日,已超过 180天没有更新
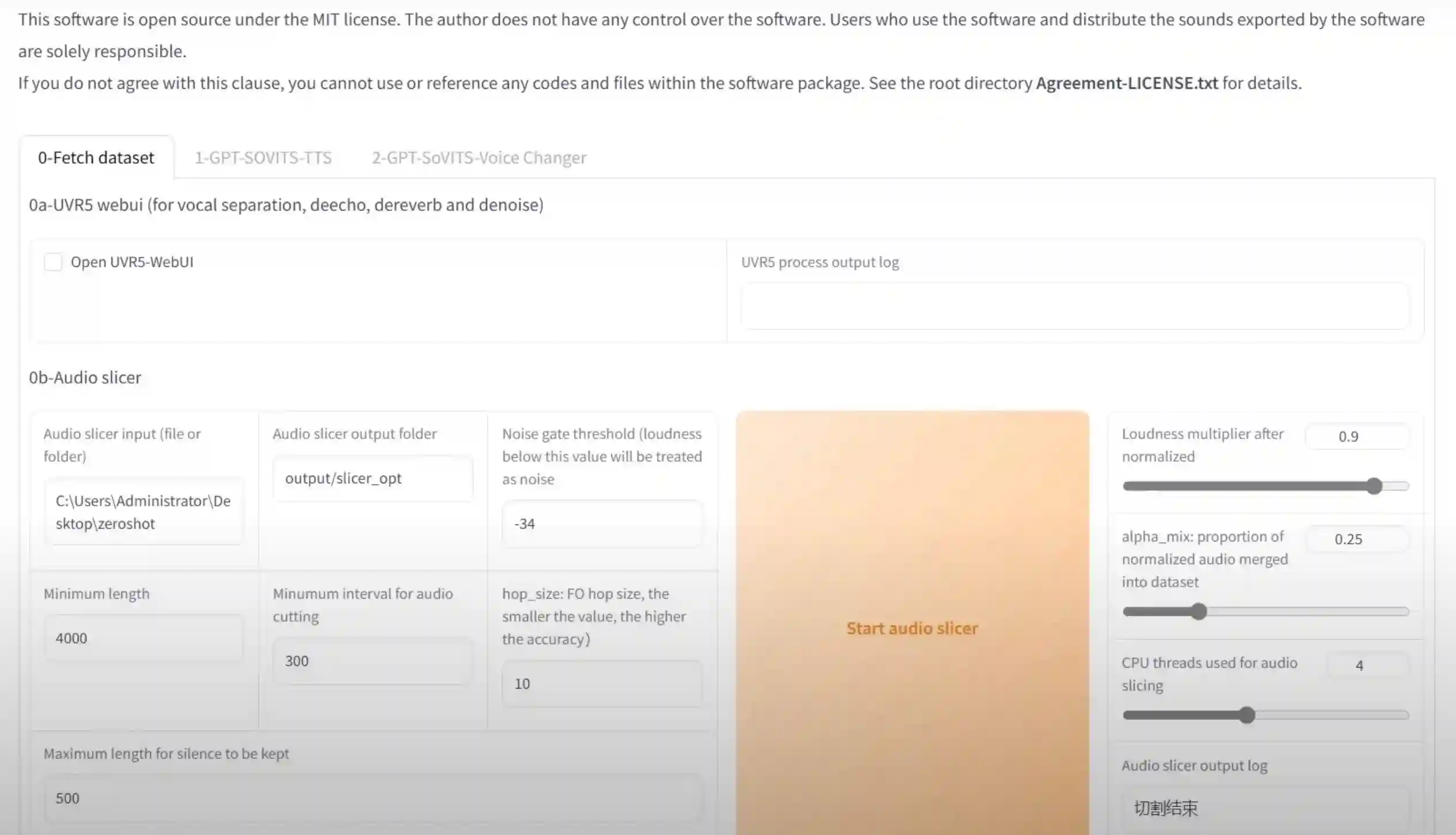
强大的少样本语音转换与语音合成Web用户界面,低成本 AI 语音克隆项目。
功能:
- 零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
- 少样本 TTS: 仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
- 跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
- WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
环境准备
如果你是 Windows 用户(已在 win>=10 上测试),可以直接通过预打包文件安装。只需下载预打包文件,解压后双击 go-webui.bat 即可启动 GPT-SoVITS-WebUI。
测试通过的 Python 和 PyTorch 版本
Python 3.9、PyTorch 2.0.1 和 CUDA 11
Python 3.10.13, PyTorch 2.1.2 和 CUDA 12.3
Python 3.9、Pytorch 2.3.0.dev20240122 和 macOS 14.3(Apple 芯片,GPU)
注意: numba==0.56.4 需要 python<3.11
Mac 用户
如果你是 Mac 用户,请先确保满足以下条件以使用 GPU 进行训练和推理:
搭载 Apple 芯片的 Mac
macOS 12.3 或更高版本
已通过运行xcode-select --install安装 Xcode command-line tools
其他 Mac 仅支持使用 CPU 进行推理
中国地区用户可使用 AutoDL 云端镜像进行体验:https://www.codewithgpu.com/i/RVC-Boss/GPT-SoVITS/GPT-SoVITS-Official
GitHub地址:https://github.com/RVC-Boss/GPT-SoVITS
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

评论0+